Humanity's Last Exam(HLE): AI 학술 능력 평가의 새로운 기준
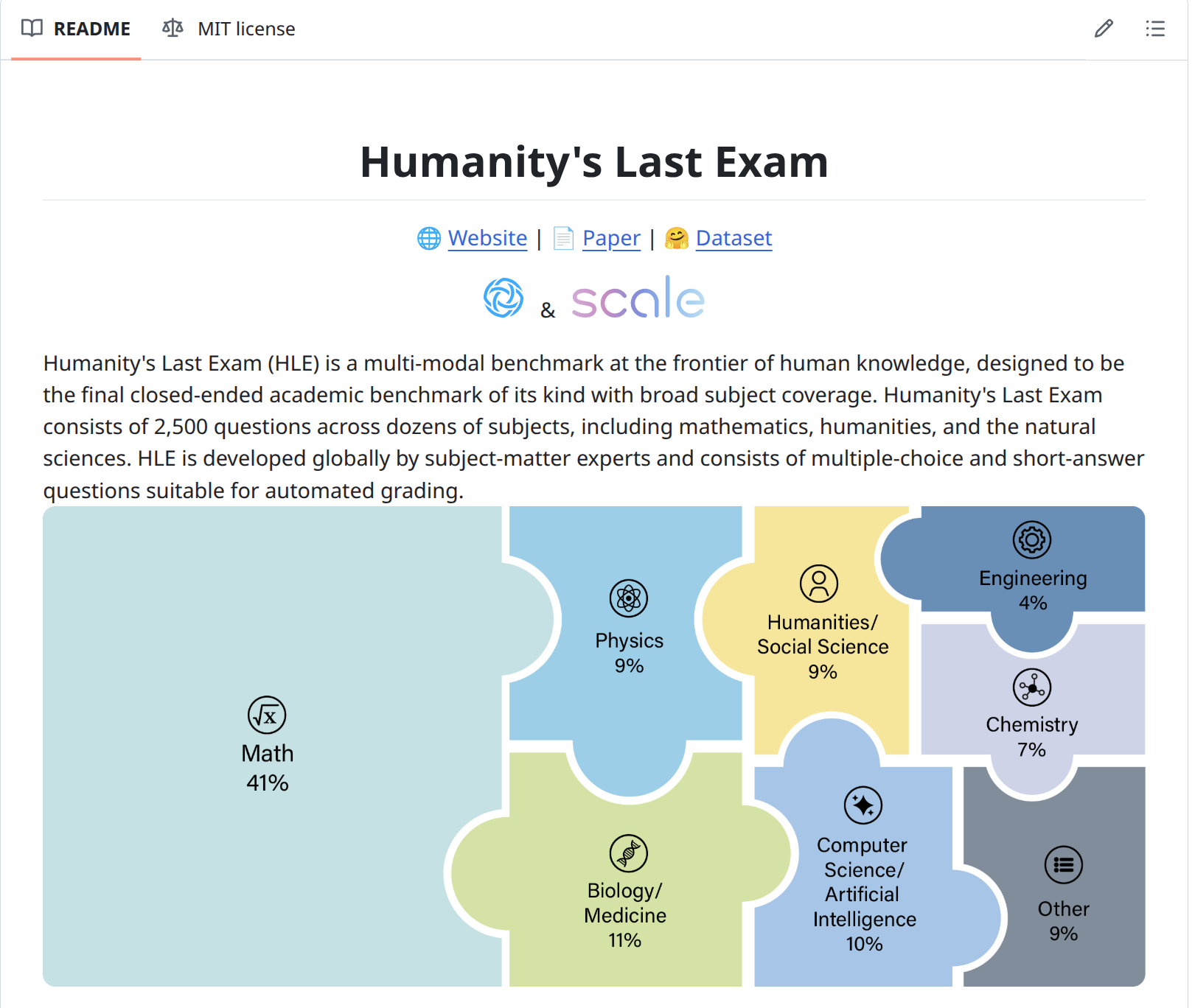
HLE 개요
Humanity's Last Exam(HLE)은 AI의 학술적 문제 해결 능력을 측정하기 위해 설계된 초고난도 벤치마크입니다. 기존 평가 방식에서 ChatGPT 등 주요 AI 모델들이 90% 이상의 정답률을 기록하면서 변별력이 사라지자, 전 세계 전문가들이 협력하여 새로운 평가 체계를 구축했습니다.
시험 구성
HLE는 총 2,500개 문항으로 구성되며, 수학, 과학, 인문학 등 100개 이상의 분야를 포괄합니다. 50개국 1,000명의 교수 및 박사급 전문가가 출제에 참여했습니다.
출제 기준은 다음과 같습니다.
- 인터넷 검색으로 해결 가능한 문제는 제외
- 대학원 수준의 전문 지식 요구
- 정답의 명확성과 검증 가능성 확보
평가 방식
HLE는 Zero-shot 방식을 적용하여 별도의 예시 없이 AI가 문제를 직접 해결하도록 합니다. AI는 먼저 풀이 과정을 서술한 후 최종 답변을 제출합니다.
채점은 자동화 시스템을 통해 이루어지며, o3-mini 모델이 심판 역할을 수행합니다. "0.5"와 "1/2"처럼 표기가 다르더라도 동일한 의미의 답변은 정답으로 인정됩니다. 또한 일부 문제는 비공개로 유지하여 AI의 사전 학습을 방지합니다.
평가 결과
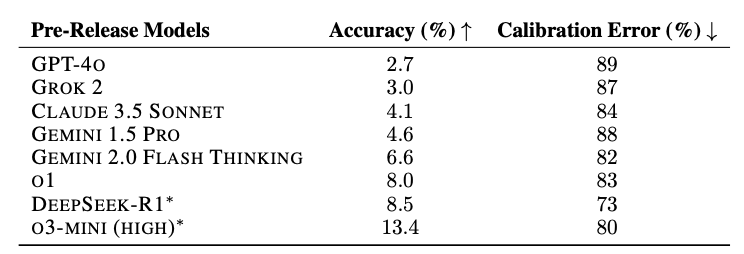
논문 발표 당시 가장 높은 점수를 기록한 o3-mini도 정확도 13% 수준에 그쳤습니다. 이는 의도된 결과로, 문제 수집 단계에서 GPT-4o, Claude 등 기존 AI가 정답을 맞힌 문제는 모두 제외했기 때문입니다.
분야별 성적도 유사한 양상을 보였습니다. 수학, 생물/의학, 물리학, 컴퓨터 과학 등 전 분야에서 AI는 낮은 성취도를 기록했으며, 이미지 없이 텍스트만 포함된 문제에서도 GPT-4o는 2.3%, o3-mini는 13.4%에 머물렀습니다.
보정 오류(Calibration Error)
정확도 외에 주목할 지표는 보정 오류입니다. 이는 AI가 자신의 정답 확률을 얼마나 정확히 예측하는지를 측정합니다. 예를 들어, AI가 90% 확신한다고 응답했을 때 실제 정답률도 90%라면 보정이 잘 된 것이고, 실제로는 30%만 맞혔다면 보정 오류가 큰 것입니다.
평가 결과, 모든 모델에서 70% 이상의 높은 보정 오류가 발생했습니다. AI가 정답을 모르는 상황에서도 높은 확신을 표현하며 오답을 제시하는 경향이 확인되었으며, 이는 할루시네이션 문제가 여전히 존재함을 시사합니다.
향후 전망
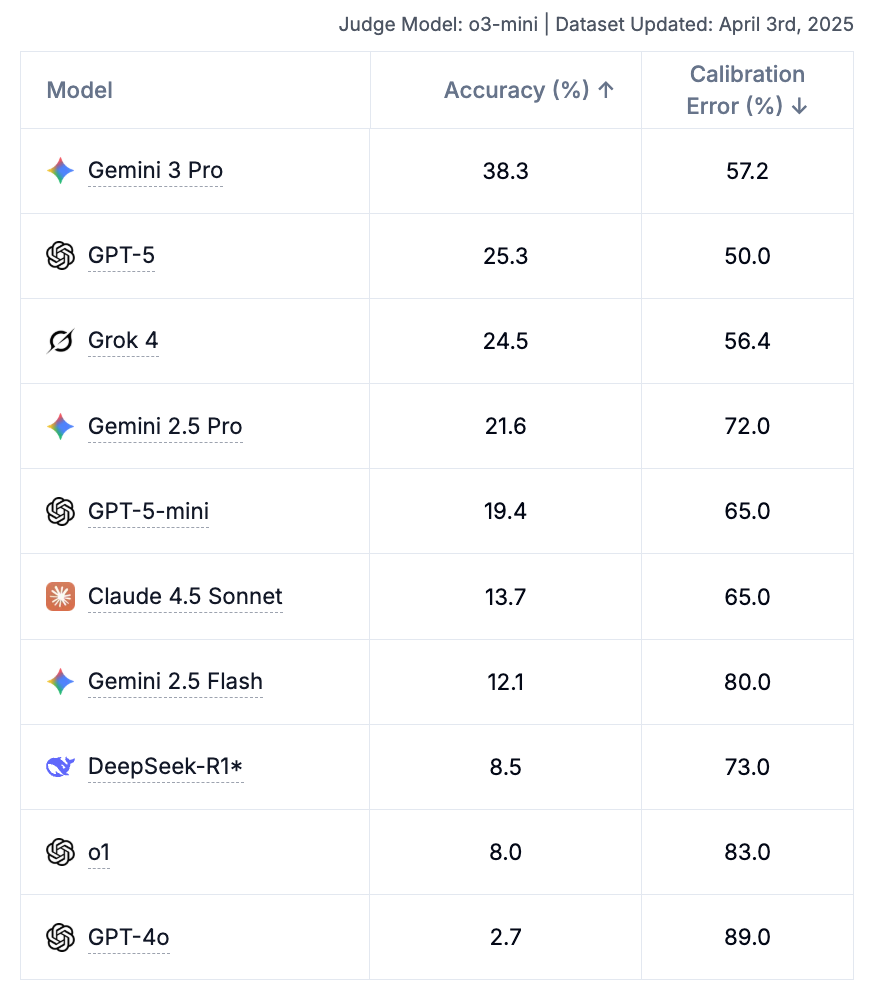
현재 AI는 전문가 수준과 상당한 격차를 보이고 있습니다. 다만 발전 속도를 고려할 때 2025년 말 정확도 50% 돌파 가능성도 제기됩니다. 이후 공개된 Claude Sonnet 4.5, Gemini 3 Pro 등 최신 모델에서는 정확도와 보정 오류 모두 개선된 수치를 보이고 있습니다.
단, HLE 고득점이 연구 수행 능력이나 AGI 달성을 직접적으로 의미하지는 않는다는 점에 유의할 필요가 있습니다.